-

Gast
KI unplugged
KI unplugged
-
KI unplugged
-
Der Kurs „Becher, Bits und Bots” enthält alle Materialien, Keynotes und ausführliche Informationen, die Sie benötigen, um das Thema in einer eigenen Unterrichtsstunde umzusetzen.
-
Die Funktionsweise einer KI kann auch ohne Computer und elektronische Hilfsmittel in vereinfachter Form gezeigt bzw. erklärt werden. In diesem Fall wird ein "Nimm-Spiel" gegen eine Pappbecher-KI gespielt.
Die Regeln sind denkbar einfach:
Zehn Stifte (Münzen, Knöpfe o.ä.) werden in einer Reihe auf den Tisch gelegt. Pro Zug nehmen zwei Spieler*innen entweder ein, zwei oder drei Stifte vom Tisch. Wer den letzten Stift nimmt, hat verloren.Bastelanleitung für die Pappbecher-KI:
Um eine KI zu basteln, die Nim spielen kann, brauchst du neun Becher in einer Reihe, die mit den Zahlen 10 bis 2 beschriftet sind. Dann schneidest du drei etwa gleich große Zettel aus und beschriftest sie mit den Zahlen 1, 2 und 3. Diese Zettel faltest du und legst sie in den Becher mit der Zahl 10. Das machst du so lange, bis in jedem Becher drei Zettel mit den Zahlen 1, 2 und 3 sind, nur der letzte Becher (mit der Zahl 2) braucht nur zwei Zettel (mit den Zahlen 1 und 2).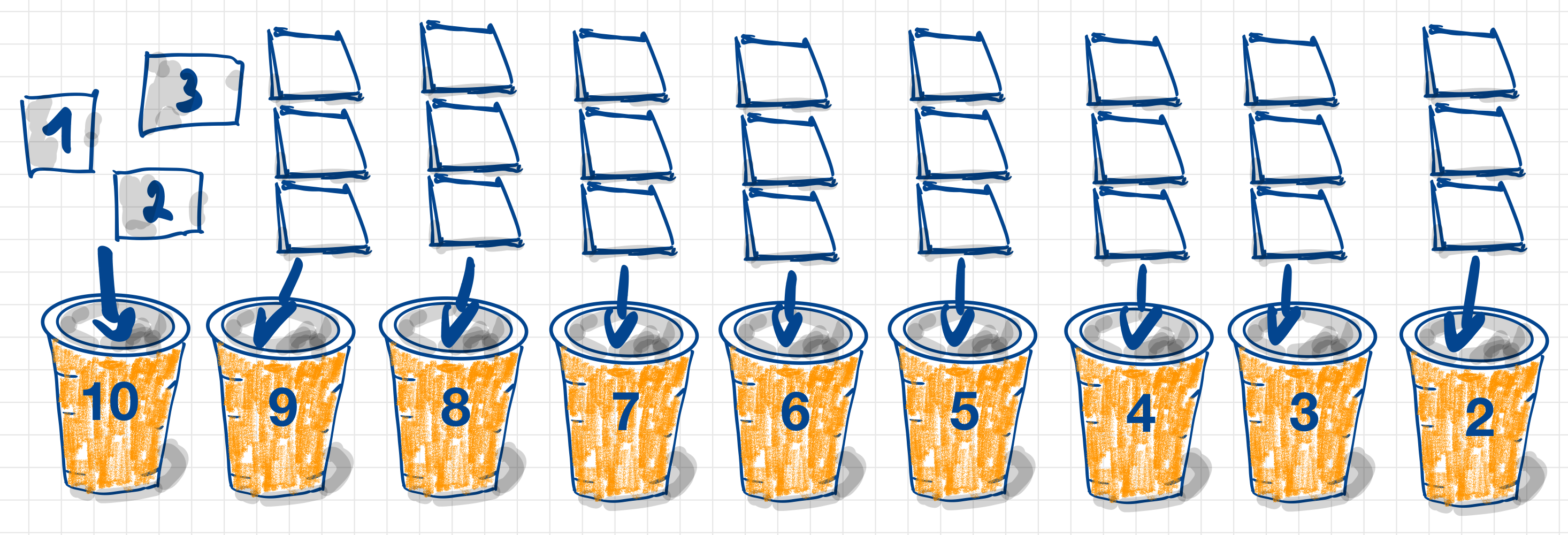
Trainieren der KI:
Das Spiel muss über mehrere Runden gespielt werden. Lege fest, wer den ersten Zug macht und behalte diese Reihenfolge während des gesamten Spiels bei.
Wenn der Spieler z.B. anfängt, darf er 1, 2 oder 3 Stifte nehmen, dann zieht die KI zufällig einen Zettel aus dem Becher mit der Nummer, die der Anzahl der noch vorhandenen Stifte entspricht. Nun zieht die KI die Anzahl der Stifte, die auf dem Zettel steht. Wenn die KI verliert, wird der Zettel des letzten Zuges aus dem Becher entfernt, in dem sich mehr als ein Zettel befindet. -
-
-
Im Prinzip kann das Nimm-Spiel auch als neuronales Netz dargestellt werden. Es besteht aus einer Eingabeschicht S1-S9, einer verborgenen Schicht und normalerweise einer Ausgabeschicht. Auf die Ausgabeschicht kann in unserem einfachen Beispiel verzichtet werden, da hier keine Entscheidungen mehr getroffen werden. Die Neuronen repräsentieren die Anzahl der Stifte. Wenn die KI verliert, wird der Zettel aus dem Becher genommen, in unserem Bild mit den Neuronen wird diese Verbindung also unterbrochen.
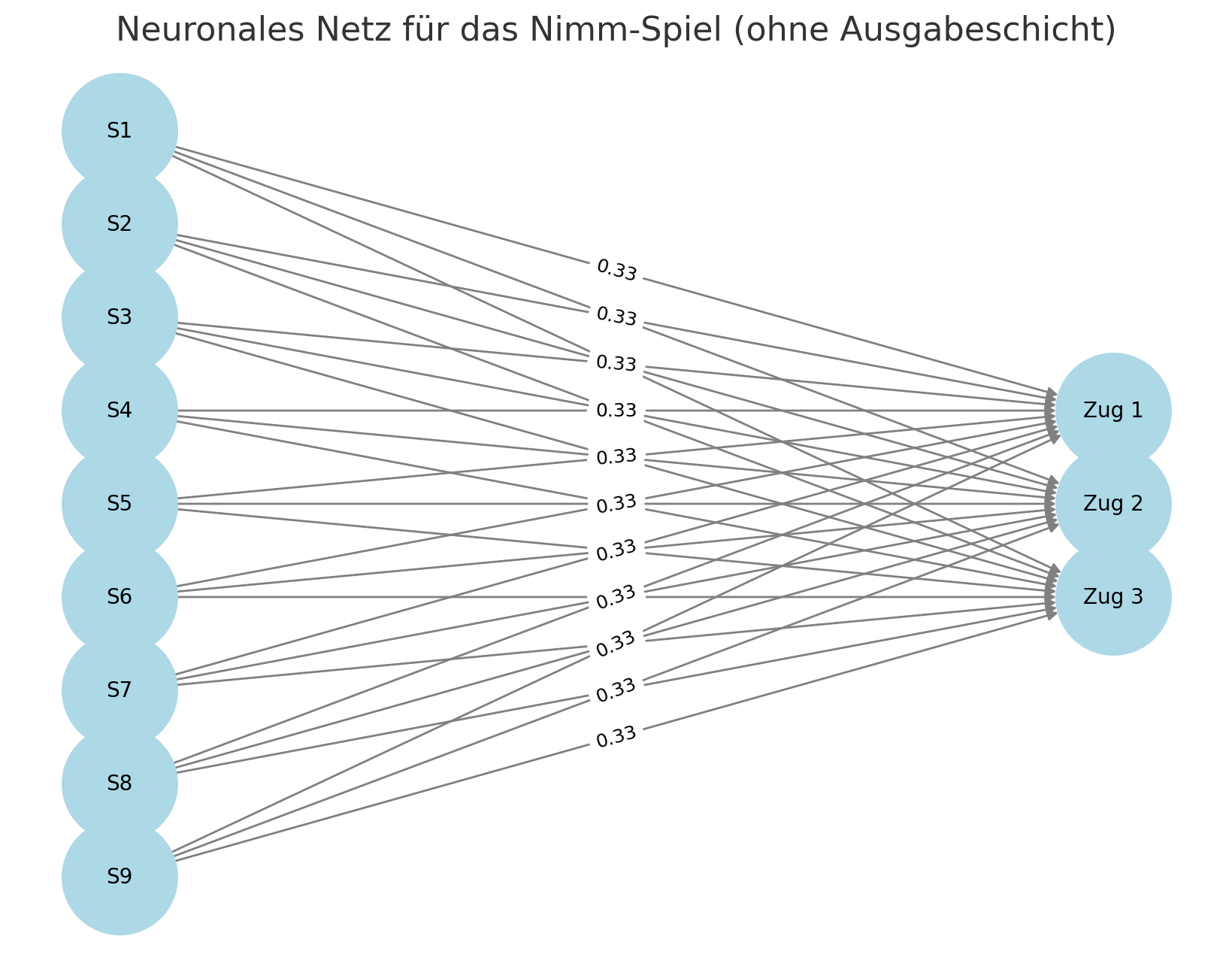
Zu Beginn ist das Netz untrainiert, d.h. die Wahrscheinlichkeit, 1, 2 oder 3 Stifte zu ziehen, ist gleich. Wenn die KI verliert, wird ein Verbindung entfernt, d.h. die Wahrscheinlichkeiten verschieben sich.
Mathematisch kann dies wie folgt formuliert werden:

 : Wahrscheinlichkeit neu
: Wahrscheinlichkeit neu : Wahrscheinlichkeit alt
: Wahrscheinlichkeit alt : Lernrate (z.B. 0,1)
: Lernrate (z.B. 0,1) : Feedback (+1 für richtige, -1 für falsch)
: Feedback (+1 für richtige, -1 für falsch)Beispiel: Falls das Netz verliert und „Nimm 1“ ein schlechter Zug war:
 = 0.2")
-
-
-
-
-
"KI-Unplugged" von Annabel Linder und Stefan Seegerer ist lizenziert unter CC BY-SA 4.0
-
-
-